
古いIntel MacでローカルLLMが動くのか、どの程度動くのかの検証です。
前回の記事でOllamaを使ってみたものの、遅過ぎて使えない。
なのでllama.cppを直接ビルドして使ったら Ollamaの約4倍の速度が出た! そんなお話です。
llama.cppのインストールからAIモデルを動かすまでをさらっとまとめてみます。
llama.cppがollamaより早いと聞いて
前回は iMac2017 に Ollama をインストール、ローカルでAIモデルを動かしてみました。
でも遅い、あまりにも遅い。
動いたことには感動だけれど 1.92 t/s くらいで字面を追うのは地味にストレス。
もう少し軽いモデルはないかと色々試してみました。
軽いモデルを使えば若干速度は上がるもののやはり性能が落ちます。
わけわかんないこと回答したり、なぜか英語と日本語のノイズ混じりの不思議な文章になっていたり。
軽さと賢さはトレードオフと知りながらも、何かないかと試していました。
結論としては・・・
ない!多分!(残念
やはり無理があったかと諦めかけたのですが、もう一つの可能性として 実行環境を変えてみたらどうなるだろう、と。
反応速度も上がるらしいと聞いたので llama.cpp を直接使ってみることにしました。
llama.cppについて
実は Ollama の内部では llama.cpp が推論エンジンとして動いています。
- llama.cpp = 「LLMをローカルで高速実行するための低レイヤー推論エンジン」
- Ollama = 「llama.cppなどを内部で利用して、モデル管理や実行を簡単にした上位ツール(ラッパー)」
Ollamaを使えば、手軽で簡単にローカルAIを試すことができます。
例えば画像を読み込ませれば楽々読み込んで説明してくれる。超簡単。
が、その反面動作はもっさりしてしまう。
スペックが足りてないのだから仕方ないけど。
そこで余計なものは省き、直接 llama.cpp を適切な設定で動かせばもう少し快適に走らせることができるかなと。
iMac2017のような古いPCではその差が顕著に出るかもしれない。
まずはHomebrew版 llama.cpp を試す
最初にHomebrewにある llama.cpp を試してみました。
brew install llama.cpp
でも結論から言うと、ダメ。
速度的には多少(気持ち程度)良くなった気がしますが、ただトークン/sを見てもさほど変わらない。
変わらないなら意味がない。(※1)
テキストチャットでの問答くらいなら問題はありません。
Githubからllama.cppを持ってきてビルド。メタルはオフ
さて、自分の環境に合わせてビルドしたらどのくらい変わるのか。
Githubなんて必要な時にたまに眺めるくらいで使ったことなんてなかったけれど、トライしてみます。
まずは cmake と git をhomebrewからインストール
brew install cmake git
次に llama.cpp のリポジトリをクローン(手元にダウンロード)します。
#git clone <リポジトリURL> <ローカル保存先パス>
git clone https://github.com/ggml-org/llama.cpp.git ~/Projects/llama.cpp
自分の環境に合わせてビルドします。
cd ~/Projects/llama.cpp
cmake -B build -DGGML_NATIVE=ON -DGGML_ACCELERATE=ON -DGGML_METAL=OFF
cmake --build build --config Release -j
オプションの説明
- -DGGML_NATIVE=ON
- 実行しているパソコンのCPUが持つ高速化命令(AVX2やNEONなど)をフルに使うように指示します。速度アップ。
- -DGGML_ACCELERATE=ON
- Apple Accelerateフレームワーク(BLAS実装)をリンクするオプション。
高精度・超高速の数学計算用機能(Accelerate)を有効にします。CPUでの計算が速くなります。 - -DGGML_METAL=OFF
- MacのGPUを使う機能(Metal)を「オフ」にし、cpuオンリーで使用する。
最初はメタルをオフにせずビルドし、画像を読む --mmproj も使って画像を説明させようとしました。
ところが何回やってもエラーで止まってしまう。
そのまま設定を詰めていくよりいっそのこと cpuオンリー にしたほうが良いように思えたのでそのように。
結果としてうまく行きました。
足を引っ張るGPUを切ったからか通常のレスポンスも、僅かにですが、早いです。
兎にも角にもインストールは完了。
最後にパスを通しておきます。
echo 'export PATH=~/Projects/llama.cpp/build/bin:$PATH' >> ~/.zshrc
source ~/.zshrc
モデルファイル(gguf)をダウンロードして実行
さぁAIの脳みそとも言うべきモデルファイルを入手します。
Hugging Face からモデルを検索してダウンロードしました。
gemma-3-4b-it-qat-Q4_K_M.gguf あたりが安定して動いてくれる気がします。
Googleが開発したオープンなAIモデル「Gemma 3」を、PCやスマートフォンなどの一般的な端末で軽量・高速に動かせるように最適化した、テキストおよび画像(マルチモーダル)対応のAIモデルファイルです。
ダウンロードが完了したらいよいよ実行します。
#パスは環境に合わせて
llama-cli -m ./models/gemma-3-4b-it-qat-Q4_K_M.gguf
起動したら hi とだけ挨拶してみます。
Loading model...
▄▄ ▄▄
██ ██
██ ██ ▀▀█▄ ███▄███▄ ▀▀█▄ ▄████ ████▄ ████▄
██ ██ ▄█▀██ ██ ██ ██ ▄█▀██ ██ ██ ██ ██ ██
██ ██ ▀█▄██ ██ ██ ██ ▀█▄██ ██ ▀████ ████▀ ████▀
██ ██
▀▀ ▀▀
build : b9691-2e88c49c9
model : gemma-3-4b-it-qat-Q4_K_M.gguf
modalities : text
available commands:
/exit or Ctrl+C stop or exit
/regen regenerate the last response
/clear clear the chat history
/read <file> add a text file
/glob <pattern> add text files using globbing pattern
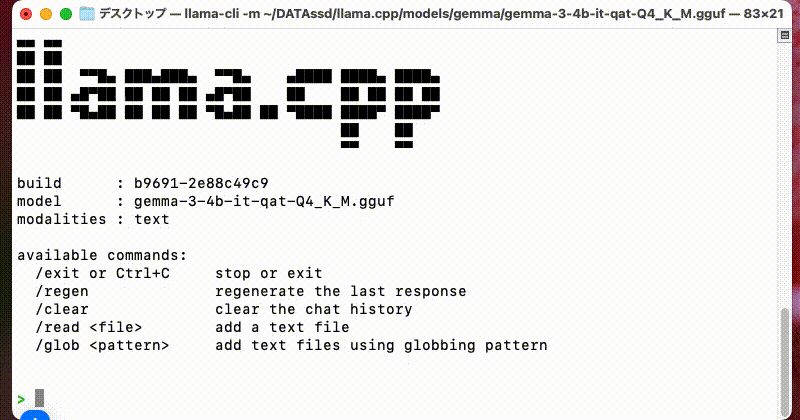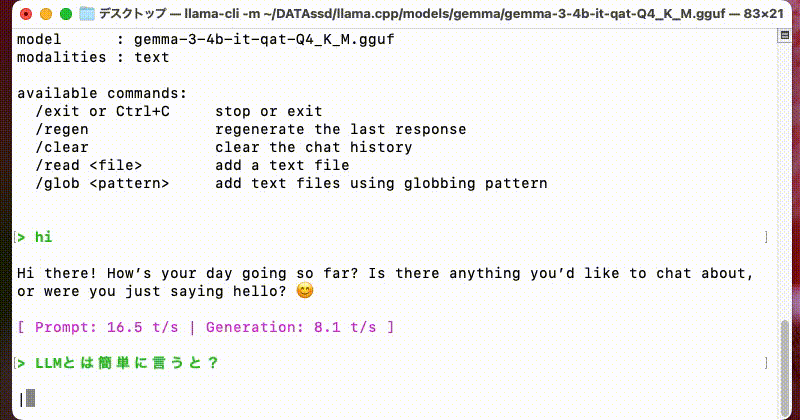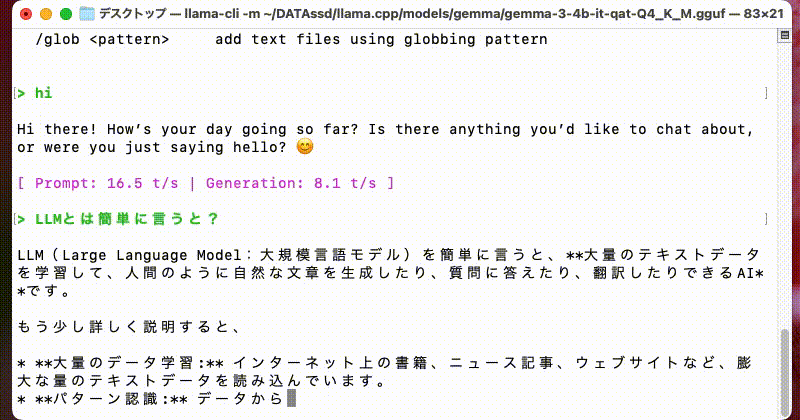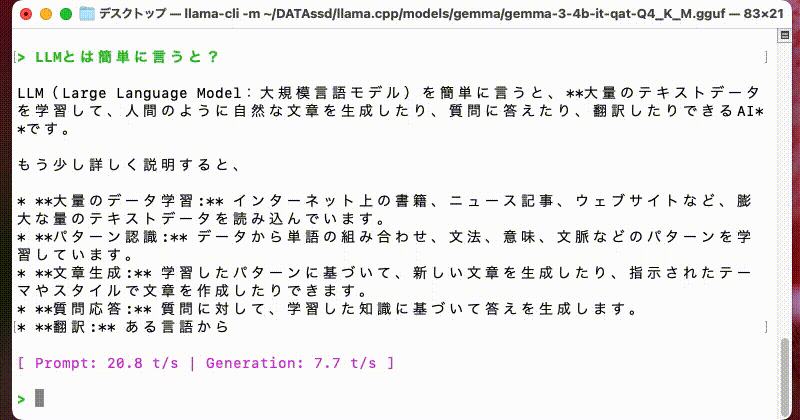
> hi
Hi there! How’s your day going so far? Is there anything I can help you with today? 😊
Just let me know what’s on your mind!
[ Prompt: 17.5 t/s | Generation: 8.5 t/s ]
>
動きましたね。Ctrl+Cで終了します。
Generation: 8.5 t/s
なので Ollama の時(※1)の 1.92 t/s や、
homebrewで入れた llama.cpp の 1.5 t/s に比べると4倍以上の速度になりました。
速度感の比較
画面収録の影響が出てますがそれでも以前よりぜんぜんマシ
前回のollamaでの実行速度
homebrewで入れたllama.cppも 9430 -> 9670 にしたら 8.1 t/s になりました。
ブラウザからアクセスして llama-ui(WebUI)も使える
これまでは llama-cli で動かしてきましたが、 llama-server で起動するとブラウザからアクセスして ChatGPT のような画面で使うこともできます。
httpサーバーを起動
llama-server -m ./models/gemma-3-4b-it-qat-Q4_K_M.ggufブラウザを立ち上げ、http://localhost:8080/にアクセスすると、llama-ui という画面にアクセスできます。
こっちの方が馴染みがありますね。画面を見ると相変わらず訳わかんないこと言ってますが笑
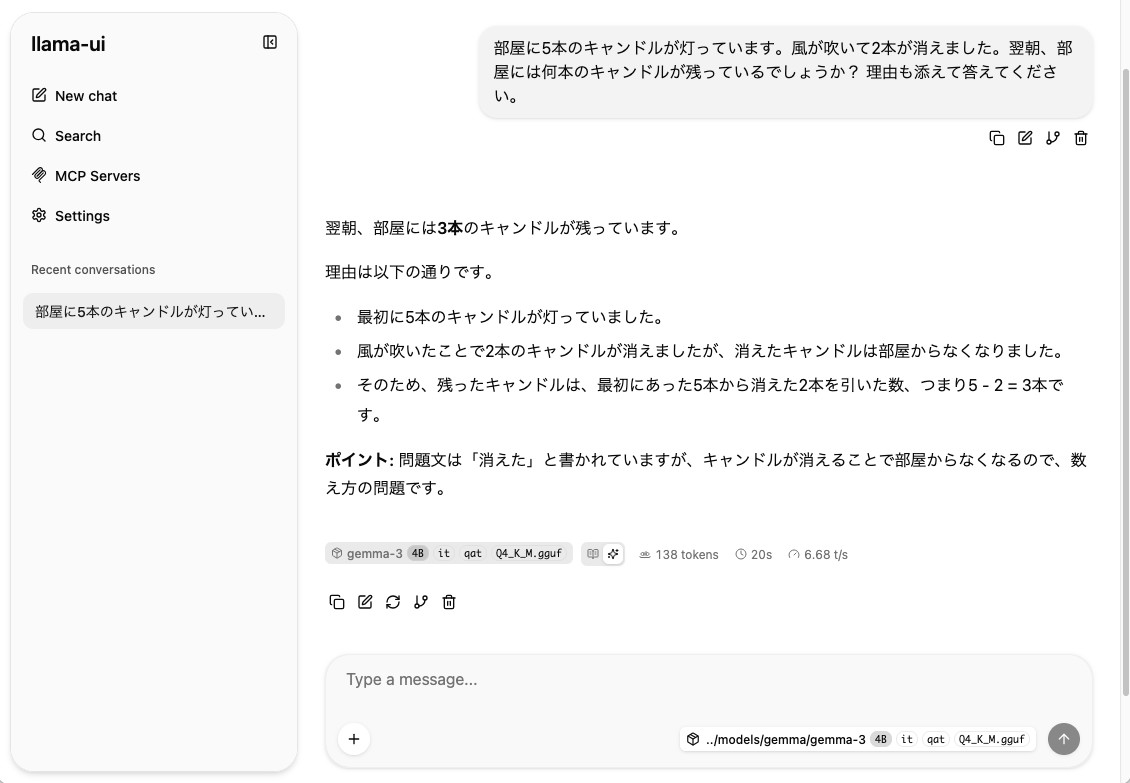
ちなみにWebUI使うとやはりちょっと遅いです。
WebUIと、ターミナルからcurlでアクセスしたものとの差を比較してみます。
別のターミナルウインドウを開き、
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{ "model": "gemma-3", "messages": [{"role": "user", "content": "部屋に5本のキャンドルが灯っています。風が吹いて2本が消えました。翌朝、部屋には何本のキャンドルが残っているでしょうか? 理由も添えて答えてください。"}]}'と打つと同じように答えてくれますが、
- WebUI → 約6.68 t/s
- curl → 約8.4t/s
1.25倍くらいの速度差があります。
まとめ
とりあえず簡単なチャットならストレスなく行えるようになりました。
本当は、ビルドしたら早くなったのでそうすると良いよーって言いたかったのですが、
この記事を書いている最中にアップデートしてみたらollamaもHomebrew版 llama.cppも普通に早くなったって言うね・・・
なんだったんじゃーーーー!
んまぁ、少しでも早く動くならいいか。
次の記事では画像を読ませて、その画像について説明させてみます。
ということで一連の流れを備忘録として記事化しました。
では。


コメント